
7月7日,在2023世界人工智能大会期间,毕马威和联想集团联合发布《“普慧”算力开启新计算时代》报告,并指出大模型的真正价值最终将体现在具体场景中,未来产业竞争也会从“规模”转向“应用”。通用人工智能若要真正走向落地,需要“普慧”算力推动大小模型协同进化。
毕马威中国数字化赋能主管合伙人张庆杰表示,未来算力发展趋势将具备两大特征:数字经济的基础设施和通用人工智能的核心动力。因此,算力将在两个关键维度上加速发展:普适(Inclusive)与智慧(Intelligent),即“普慧”。
“普慧”算力强调立足实际使用需求,安全合理的使用数据,以高效的算法,实现可靠的数字化、智能化效果。其中,“普”为“普适”,强调以自然交互的方式提供算力,算力将成为人人可得、人人可用、人人适用的“3A”型基础资源,旨在让人们即取即用算力而不必见;“慧”为“智慧”,强调以认知驱动的方式提供算力,算力将具备自适应、自学习、自进化为代表的“3S”智能,能够让人们随需使用算力而不必问。
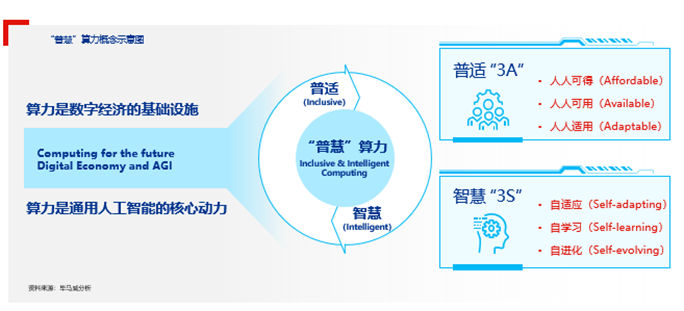
未来算力将在普适和智慧两个维度上加速发展
自2022年底以来,从OpenAI的ChatGPT、谷歌的Bard,再到百度的“文心一言”、阿里云的“通义千问”……全球科技公司和机构纷纷推出大模型产品。据不完全统计,仅在国内,半年内就有81个大模型发布。
毕马威认为,目前大模型训练都在云端实现,所用算力是中心化的,精度要求高且成本高,意味着大模型落地必然会面临能耗和性能平衡的难题。破局之道在于大小模型协同进化,即在利用大参数训练完大模型之后,通过高精度压缩,将大模型转化为端侧可用的小模型,大模型相当于超级大脑,小模型相当于垂直领域专家,共同推动AGI落到实处,这也是“普慧”算力释放价值的过程。
此外,要想实现通用人工智能的落地,算力降本问题也迫在眉睫,而这也离不开大小模型的协同。放眼全球,当下除了科技巨头外,几乎没有企业承担得起大模型训练的高昂成本。而算力降本并非减少投入,而是利用有限资金获取更多元的算力。报告指出,在大模型走向场景化、实用化的过程中,将会形成“大模型+小模型”的产业生态,即大型企业负责搭建底层通用大模型,中小型企业在大模型的基础上搭建面向特定任务场景的小模型,相较大模型而言,小模型训练的资金投入更低,且更能满足不同主体在不同阶段、不同场景中的不同算力需求,小模型训练需求的算力增量仍然可观。
可以预见,随着各行业全要素、全流程、全场景迈向数字化和智能化,数据架构和业务架构将不断向更强大的算力平台上迁移,实现“业务、数据、算力”之间的高效联动,从而保证算力资源按需匹配、精准赋能,真正推动算力转化为现实的生产力。













